


New frontiers in medical AI
Issue 73 l Eka’s Weekly Roundup (3 May 2024)

Gemini beats GPT 🗞️
Med-Gemini is Google’s latest health-dedicated LLM. Med-Gemini was built on the foundations of Gemini 1.0 and 1.5, which were released at the very end of December 2023. Google published a paper highlighting the differences between GPT and Gemini, and the results are pretty extraordinary.
Wait, what is Gemini again?
As a reminder, Gemini is is Google’s generalist LLM used to ‘supercharge your creativity & productivity’. This is Google’s response to GPT’s impact on its search business. As a tangent, Google Chrome users will soon be able to access Gemini AI straight from the search bar.

Gemini is largely trained on Google’s own data. As Google states, “Gemini is trained on first-party Google Cloud code as well as selected third-party code. You're responsible for the security, testing, and effectiveness of your code, including any code completion, generation, or analysis that Gemini offers you”. There’s also been some publicity about how AI is rewriting the internet, but we will leave that for another time.
Going from a generalist LLM to ‘as good as a doctor’
Med-Gemini has transformed Gemini’s underlying technology to make it more medicine-specific (shown below). The model has been specialised with additional training on clinical-specific integrations. The underlying Gemini models are highly multi-model however and so the fine-tuning for Med-Gemini required less data compared to previous generations of medical AI systems.

The use cases are impressive across patient dialogue and medical compliance
Multimodal data (i.e. image and text) is well understood by Med-Gemini. Initially, the user in the example below asks Med-Gemini-M 1.5 about itchy lumps present on their legs and arms. Subsequently, the model prompts the user to submit an image of the lumps. Upon receiving the image depicting the suspicious lesion, the model follows up with another question and proceeds to accurately diagnose prurigo nodularis, offering recommendations for subsequent steps and potential treatment avenues.

The following example is more around medical compliance. The example below is Med-Gemini-M 1.5 scrutinising a video excerpt sourced from the Cholec80 dataset. It is evaluating whether the clinician attained the Critical View of Safety (CVS) during a laparoscopic cholecystectomy procedure, aimed at gallbladder removal through minimally invasive means. The model determines whether the three defining criteria for achieving CVS are satisfied, providing a comprehensive explanation for each criterion individually.

Do clinicians really care?
Below, we can see that Med-Gemini’s long-context processing on medical instructions far outperforms previous state of the art LLMs.

One piece that stood out to us was the real preference of Med-Gemini compared to experts by clinicians. Almost all clinician raters preferred Med-Gemini for referral generation and medical simplification. Summarisation was a bit more mixed, but still >60% preferred Med-Gemini.

Still, a long way to go before we get to mass adoption
Med-Gemini’s predecessor MedPalm was being tested by mid 2023 by a limited group of customers. These included for-profit hospital giant HCA Healthcare, academic medical system Mayo Clinic and electronic health records vendor Meditech.
There haven’t been many updates since the partnerships were announced last year, which has been viewed as a mild negative by some (see this blog here from AI Health Uncut).
Still, Google has published some thought pieces & videos, like the one below, on how transformational the technology could be.
Beyond Med-Gemini, Abridge and other AI tools have had their moment in the sun.
One key buying decision for these Gen AI tools is to minimise clinical burnout. For example, one clinician was quoted saying "we understand the profound impact that AI solutions can have on our clinicians as well as patient care and are excited to introduce Suki to our network. We are excited to see how the solution will boost engagement and reduce burnout."
Suki has said that it can help clinicians complete notes 72% faster. It also claims a 48% decrease in amended encounter rates.
Separately, Abridge recently raised $150m to build their own AI model. They are already working with clients like Emory, Sutter Health, and Kansas Health.
However, our sense is that this AI frontier is still definitely in the early stages and has not reached very high levels of utilisation within the care system, relative to its potential.

Does first mover really win the crowd?
Health AI adoption has been notoriously slow for a few reasons including regulatory hurdles, EHR workflow integrations, and clinical conservatism.
For example, many AI applications need to be regulated under the FDA’s ‘Software as a Medical Device’ regulation, as we wrote about in our Health AI piece last year. The key questions on regulatory pathways include:
(1) What is the scope of products that are available for my intended use?
(2) How were the models trained and how were they validated?
(3) Once purchased, will an AI application perform as expected in my practice? How can I monitor the performance of the model after deployment?
Then, there is pressure to show immediate ROI figures in order to convince payers to invest in the solution. In the UK, the National Health Service announced in 2019 that it would begin to reimburse for AI-based care in 2020 to incentivise more rapid adoption. This doesn’t seem to have impacted broader AI deployment or health outcomes, at a population level.
Finally, there is large perceived risk among end-users. This comes down to concerns around health data, privacy, or cyber security.
For this reason, healthcare adoption is proving to be slower than consumer adoption of Gen AI.

Putting it all together: MedGemini achieves state of the art performance on 10 out of 14 medical benchmarks
This chart compares Med-Gemini against both the previous state-of-the-art (SoTA) and the most effective GPT-4 methodologies across text-based, multimodal, and tasks requiring extensive context comprehension.
In cases where researchers could not locate reported figures for GPT-4 (or GPT-4V) in existing literature, they conducted evaluations on identical test sets using public APIs for a direct comparison, employing the same few-shot prompts as the corresponding Med-Gemini model along with specific instructions to ensure proper formatting of outputs.
In the widely recognized MedQA (USMLE) benchmark (useful for diagnostics), the top-performing Med-Gemini model attains state-of-the-art (SoTA) accuracy of 91%. This surpasses the performance of Google’s previous leading model, Med-PaLM 2, by 4.6%.
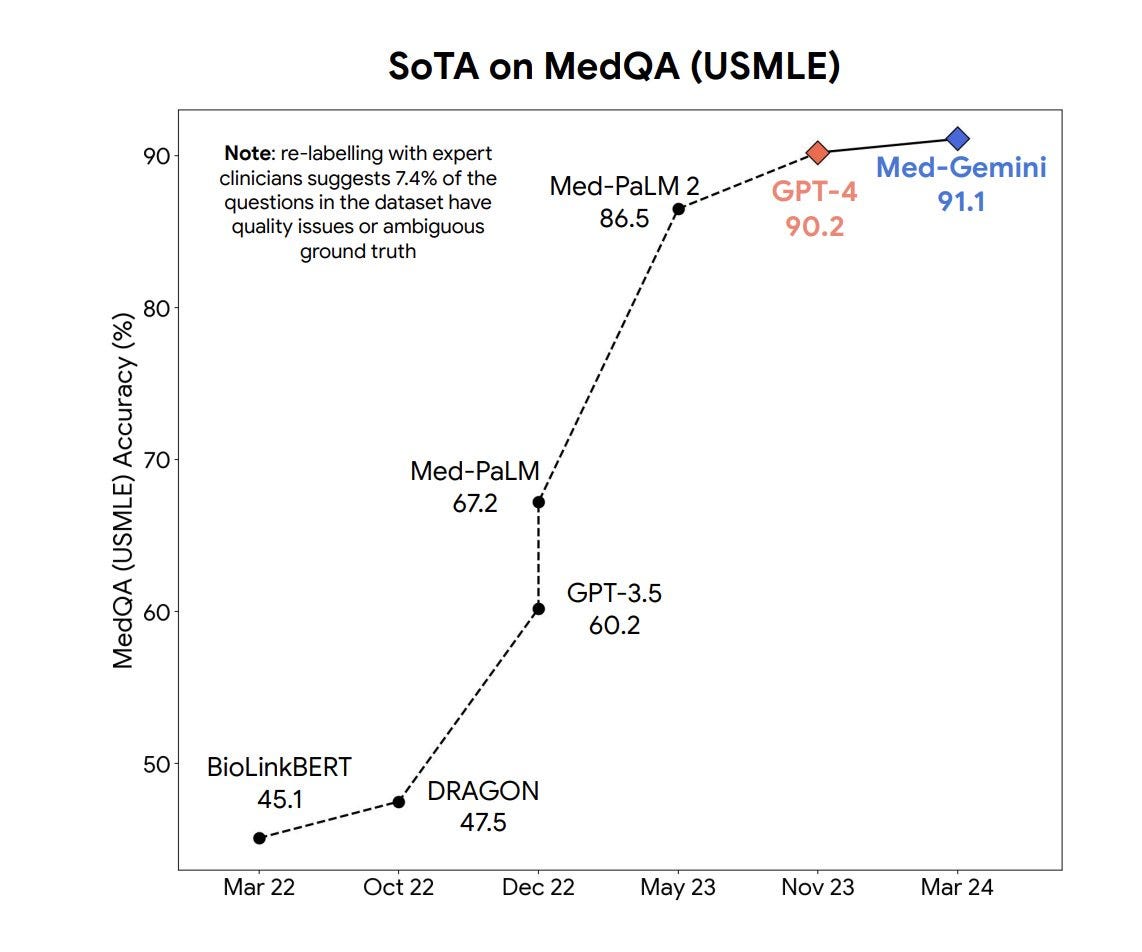
Med-Gemini has now set a new standard for medical AI LLMs across diagnostics and treatment.
Portfolio News 🎉
Urban Jungle has raised £8m! Urban Jungle uses technology to better insure consumers and reduce fraudulent claims, enabling them to offer competitive prices. Headquartered in London, the team is now 70 employees and has garnered a customer base of over 200,000.
Week in Impact Articles ✍🏽
Monday: Daniel Ek’s Next Act: Full-Body Scans for the People
Tuesday: Vinted reaches profitability and reports 61% revenue growth last year
Wednesday: Biopharma and medtech venture investments trend up in Q1
Thursday: Cancer vaccines are having a renaissance
Friday: Pitchbook’s Carbon & Emissions Tech Report
3 Key Charts 📊
1. Ups and downs of Tesla’s share price

2. Winds of change on the UK power grid

3. (And the inverse..) a decreasing fossil fuel dependence for British homes

Getting in Touch 👋.
If you’re looking for funding, you can get in touch here.
Don’t be shy, get in touch on LinkedIn or on our Website 🎉.
We are open to feedback: let us know what more you’d like to hear about 💪.